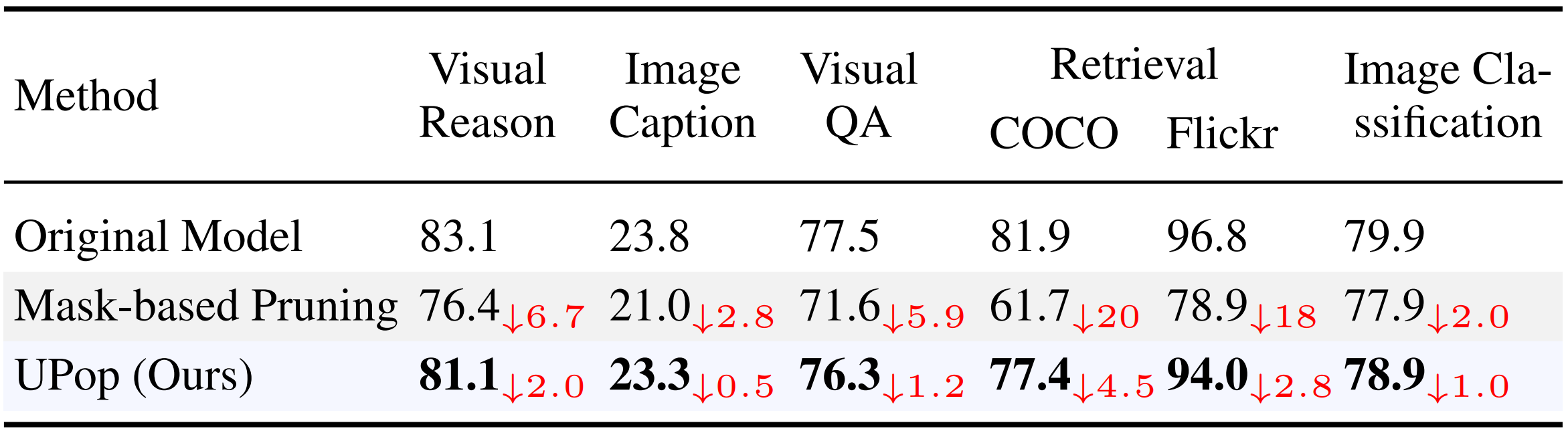
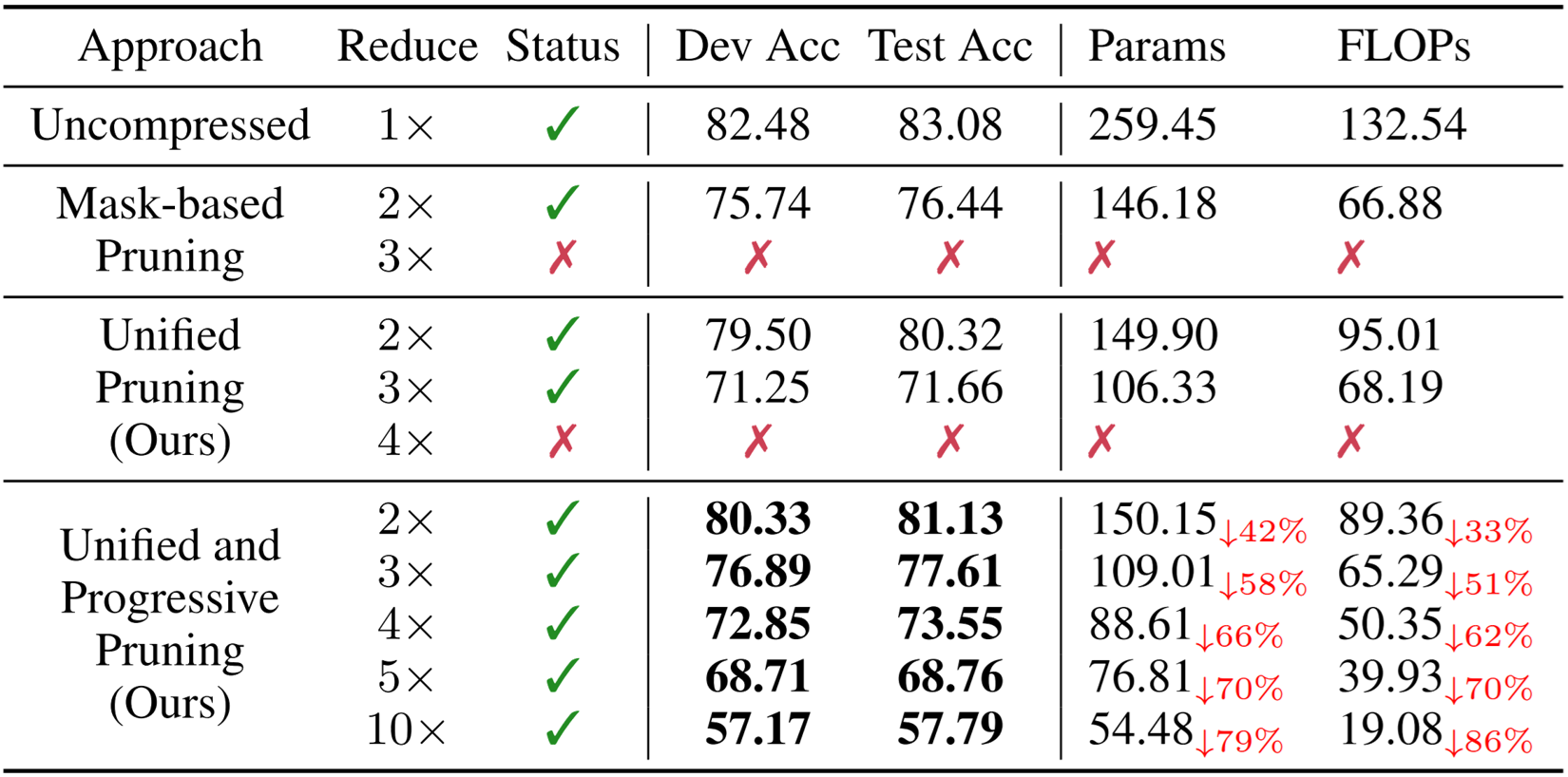
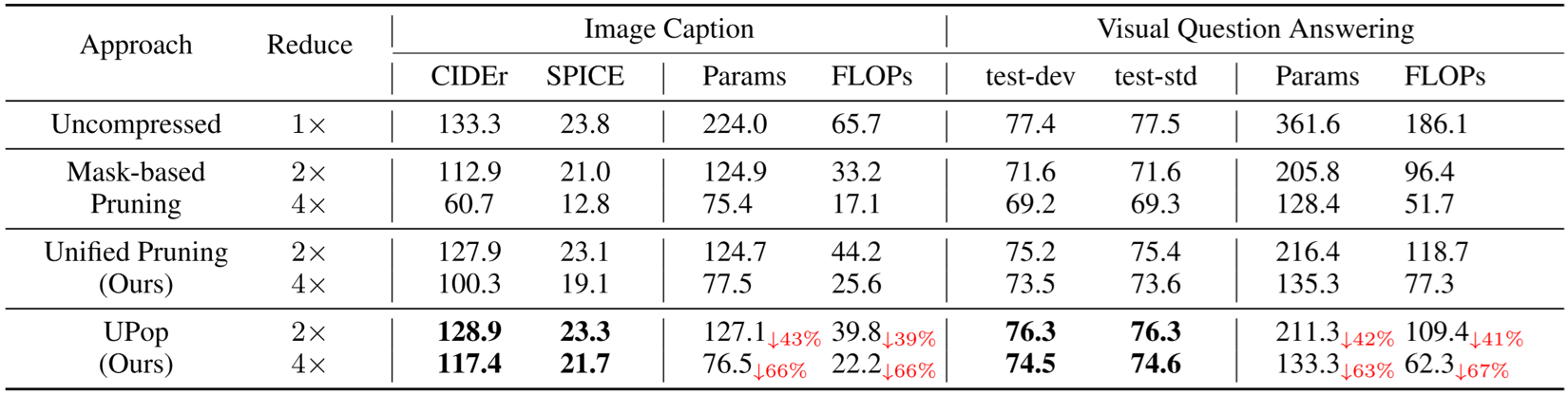
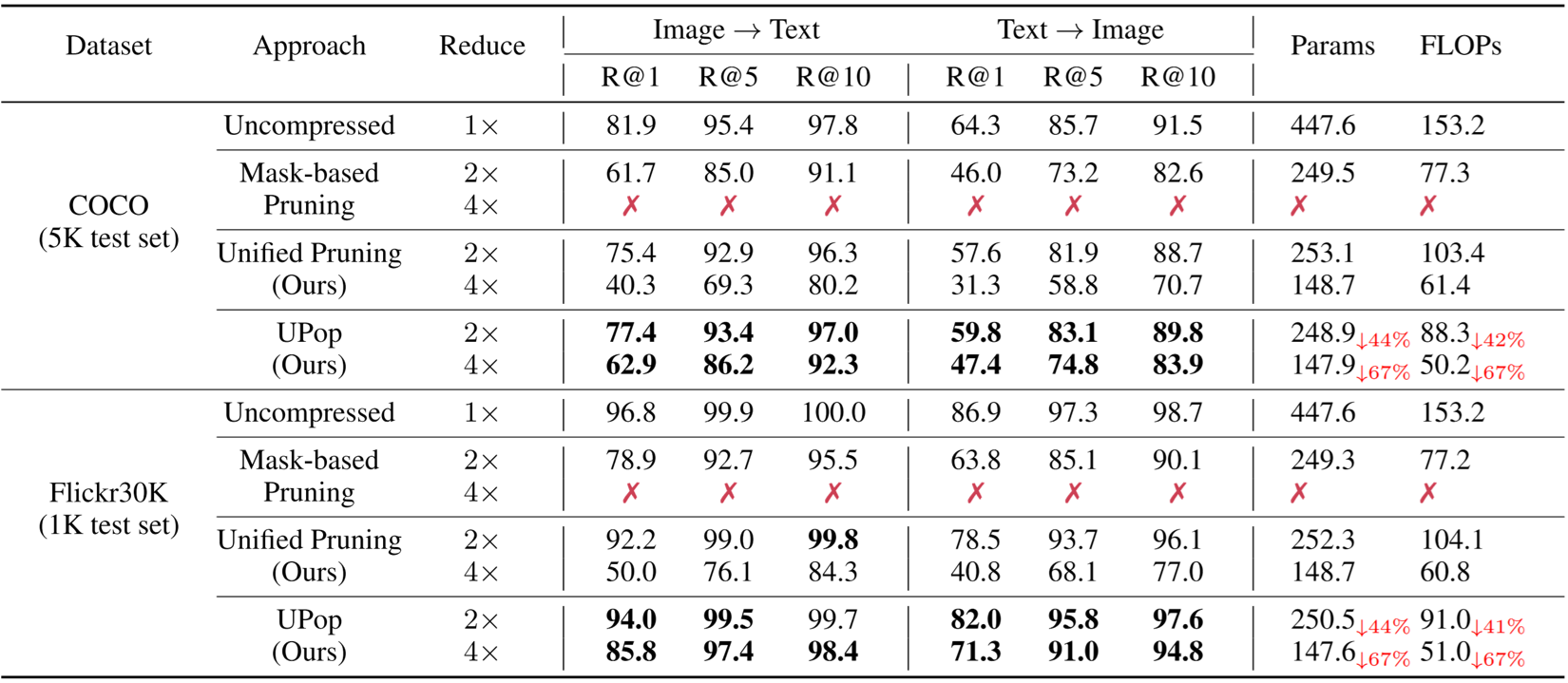
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities.
Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how
to compress multimodal models, especially visonlanguage Transformers, is still under-explored.
This paper proposes the Unified and Progressive Pruning (UPop) as a universal vison-language Transformer compression framework,
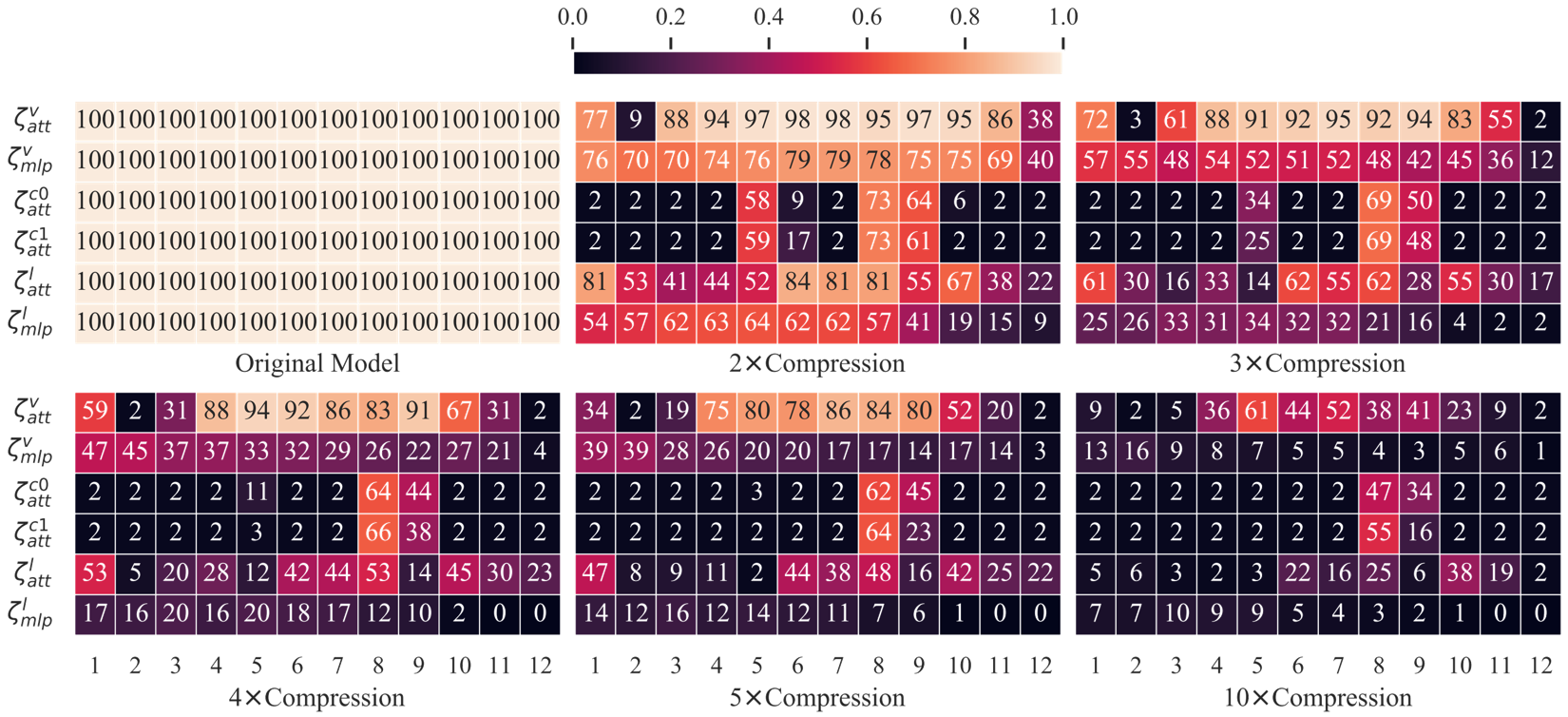
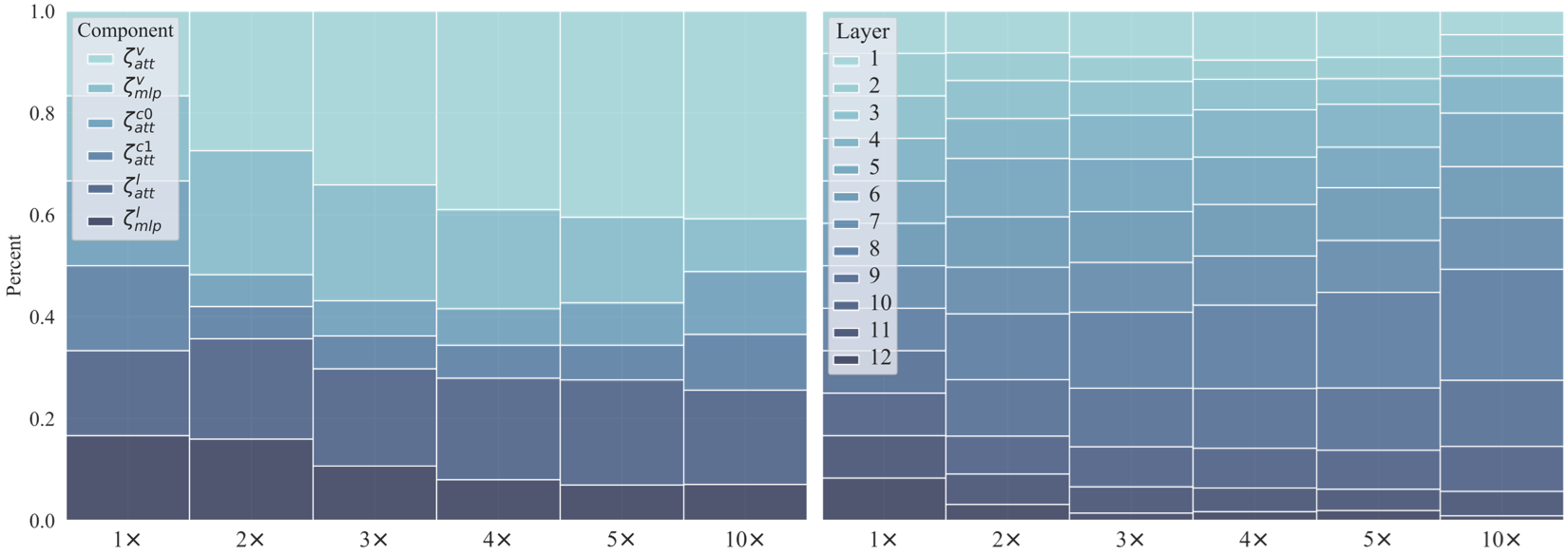
which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from
the original model, which enables automatic assignment of pruning ratios among compressible
modalities and structures; 2) progressively searching and retraining the subnet, which maintains
convergence between the search and retrain to attain higher compression ratios. Experiments on
various tasks, datasets, and model architectures demonstrate the effectiveness and versatility of
the proposed UPop framework. The code is available at https://github.com/sdc17/UPop.